この記事は グラフィックス全般 Advent Calendar 2024 の 16 日目の記事となります。
はじめに
WebGPU が昨年 5 月に Chrome 113 で利用可能になり、それから 1 年半ほどが経ちました。 まだ FireFox や Safari など利用できない環境もありますが、これから普及も進んでいくと思いますし、WebGPU に興味や期待を寄せている方も多いのではないでしょうか。
今回は GPGPU の勉強のために取り組んだ WebGPU によるハッシュの実装の話をしようと思います。 寒い時期なので GPU の熱で暖をとりたい方におすすめの内容です。
デモで使用したコードはこちらの GitHub リポジトリに置いてあります:
負荷の高い処理を実行するため、 大量の電力を消費したり、環境によっては実行中にブラウザが固まったりクラッシュするなどの可能性があります。 ご注意ください。
なぜ MD5 を実装したのか
私自身がセキュリティにかかわる仕事をしていることもあり、「MD5 だと N 時間でハッシュの総当たりができる(から危ない)」みたいな話をよく耳にします。
たとえばこちらの記事では、「数字と大文字と小文字と記号 (^*%$!&@#)」を用いた 8 文字のパスワードの MD5 のハッシュ値が RTX 4090 を使うと 1 時間程度で総当たりできる、と書かれています。
このように、ハッシュの計算は GPU で扱われるポピュラーな題材の一つとなっていることや、MD5 が実装の難易度的にもちょうどよかったというのが主な理由になります。
MD5 の概要
MD5 は RFC 1321 で規定されているハッシュアルゴリズムです。 現在は安全性が問題視されており、暗号化などセキュリティにかかわる場面で使われることは少なくなっていますが、データの破損検知のチェックサムなどまだまだ使われる場面はあるかと思います。
詳しくは RFC の定義を見てもらえばよいと思いますが、簡単に処理の概要を説明します。 (各操作がどのような意味を持っているのかまでは理解しなくてよいです。)
関数 F ~ I を以下のように定義します:
F(X,Y,Z) = XY v not(X) Z G(X,Y,Z) = XZ v Y not(Z) H(X,Y,Z) = X xor Y xor Z I(X,Y,Z) = Y xor (X v not(Z))
これら 4 つの関数と以下の初期値を持つ
内部状態 A ~ D、
word A: 01 23 45 67 word B: 89 ab cd ef word C: fe dc ba 98 word D: 76 54 32 10
および 64 バイトの入力 X を用いて以下の処理を実行します:
AA = A BB = B CC = C DD = D // ラウンド 1 [ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4] [ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8] [ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12] [ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16] // ラウンド 2 ~ 4 ~省略~ A = A + AA B = B + BB C = C + CC D = D + DD
最初に A ~ D の値を AA ~ DD に保存しておきます。
ラウンド 1 では [abcd k s i] は関数 F を用いて a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s) で定義され、上記の順番で実行します。
ここで、X[k] は 64 バイトの入力を 4 バイト区切りにしたときの k 番目、 T[i] は 4294967296 * abs(sin(i)) の整数部分、<<< s は s ビットだけ左にローテートする演算になります。
ラウンド 2 以降も関数 G ~ I について同様の処理がありますが、ここでは省略します。
最後に A = A + AA のように、保存しておいた AA ~ DD を使って A ~ D の値を更新します。
今回扱う範囲では入力は 4 ~ 8 バイト程度なので省略しますが、大きな入力を扱う場合は 64 バイトごとに上記の処理を実行する必要があります。
最後まで実行した後の A ~ D の値を結合した 16 バイトのデータが MD5 のハッシュ値となります。
WebGPU による MD5 の実装
RFC に記載されている C のコードを参考に、概要で説明した処理の主要な部分を WGSL (WebGPU の処理を記述する言語) で以下のように実装しました。 ソースコードの全体を見たい方は GitHub リポジトリの方を参照してください。
関数 F ~ I は次のように実装しました:
fn F(x: u32, y: u32, z: u32) -> u32 { return (x & y) | (~x & z); } fn G(x: u32, y: u32, z: u32) -> u32 { return (x & z) | (y & ~z); } fn H(x: u32, y: u32, z: u32) -> u32 { return x ^ y ^ z; } fn I(x: u32, y: u32, z: u32) -> u32 { return y ^ (x | ~z); }
ラウンド 1 の [abcd k s i] は 関数 FF として次のように実装しました:
fn ROTATE_LEFT(x: u32, n: u32) -> u32 { return (x << n) | (x >> (32 - n)); } fn FF(a: ptr<private, u32>, b: u32, c: u32, d: u32, x: u32, s: u32, ac: u32) { *a = b + ROTATE_LEFT(*a + F(b, c, d) + x + ac, s); }
実装の都合上 X[k] と T[i] は添え字ではなく値を渡すようにしています。
また、FF の第 1 引数は、関数内で値を更新するためにポインタ型にしています。
正しく動くか確認するために、ランダムな 4 バイトのデータの MD5 値を計算するデモ 01 を作りました:


うまく動いてそうですね。
MD5 の総当たり
ここからが本番です。 特定の MD5 ハッシュ値を持つ入力バイト列を GPU のパワーで探します。
GPU のパワーを効率よく利用するには、並列で実行できるように入力をうまく作る必要があります。 ここが一番頭を使う部分だと思いますが、今回紹介するデモでは 4 バイト (32 bit) の入力を以下の組み合わせで生成します:
- ワークグループ数: 14 bit
- ワークグループサイズ: 6 bit
- シェーダー内ループ: 残り (32 - 14 - 6 = 12 bit)
各値は手元の環境でいい感じに動くように調整したものなので、必要があればそれぞれの環境に合わせて調整してみてください。
「ワークグループ数 × ワークグループサイズ」が実行される処理(ワークアイテム)の数になりますが、それぞれ連番の ID が振られていて組み込み引数の global_invocation_id で参照できます。
残りの 32 bit に足りない部分はシェーダー内の for ループで探索します。
ワークグループについて知りたい場合は、こちらの記事が参考になります: WebGPU - コアの全てを canvas 抜きで (翻訳) - inzkyk.xyz
以上から、4 バイトの入力 word1 を生成する部分の実装は以下のようになります:
@compute @workgroup_size(1 << ${WORKGROUP_SIZE_BITS}) fn main(@builtin(global_invocation_id) global_id : vec3u) { for (var i = 0u; i < 1 << (32 - ${WORKGROUP_COUNT_BITS} - ${WORKGROUP_SIZE_BITS}); i++) { // ~省略~ let word1 = (global_id.x << (32 - ${WORKGROUP_COUNT_BITS} - ${WORKGROUP_SIZE_BITS})) | i; // ~省略~
${WORKGROUP_SIZE_BITS}, ${WORKGROUP_COUNT_BITS} は JavaScript で具体的な値に差し替える部分になります。
また、高性能な GPUを使うと 4 バイト (4,294,967,296 通り) の総当たりはすぐに終わってしまうため、追加の 4 バイトの入力 word2 を uniform 変数で与えます:
@group(0) @binding(0) var<uniform> word2: u32;
こちらは上位の 4 バイトになるので、そこまで高速に値を設定する必要はないため、JavaScript 側でインクリメントする想定です。
以上を実装したデモ 02 がこちらになります:
※ 高負荷注意です
このデモはハッシュ値の先頭 5 バイトがすべて 0 の入力を探索するように実装しています:
// 先頭 5 バイトが 0 の入力が見つかったら result に値を設定する if (A == 0x00000000u && (B & 0x000000ffu) == 0x00000000u) { result = word1; break; }
高性能な GPU がない場合、実行がなかなか終わらないと思うので、先頭 3 バイトがすべて 0 の入力を探す軽量版のデモも置いておきます:
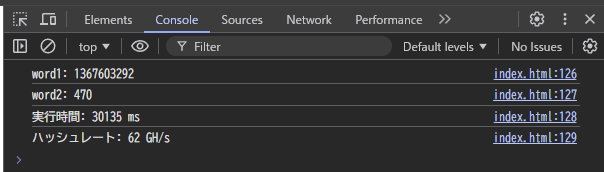

見つかった入力のハッシュ値を Python で確認したところ、確かに先頭 5 バイトがすべて 0 になっています。
私の環境 (RTX 4080 Super) では 60 GH/s 程度の実行速度になりました。
冒頭にあげた「数字と大文字と小文字と記号 (^*%$!&@#) を用いた 8 文字のパスワード」の組み合わせは (10 + 26 + 26 + 8) ** 8 通りなので、大体 2 時間半くらいで総当たりできる計算 (((26 + 26 + 10 + 8) ** 8 / (60 * (1024 ** 3))) / 3600 ≒ 2.5) になります。
それなりのパフォーマンスは引き出せているんじゃないでしょうか。
ちなみに実行中の GPU の使用率や温度はこんな感じです:
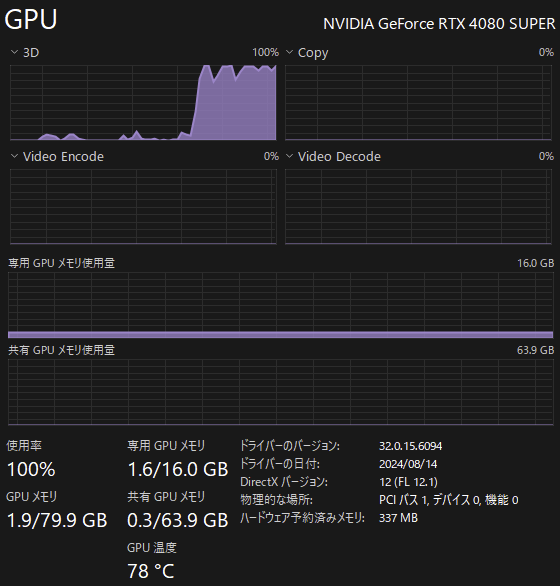
これで今年の冬も乗り越えられそうですね。
まとめ
WebGPU で MD5 の総当たりを簡単にではありますが実装してみました。
GPU のプログラミングはこんな感じで意外と気軽に試せる環境があります。 これまで興味はあったけど手を出せていなかった方は、これを機に WebGPU で GPU プログラミングを始めてみてはいかがでしょうか。
今回は単なるバイト列の総当たりでしたが、「数字と大文字と小文字と記号」だけに絞った総当たりもすぐに実装できると思います。 これは演習問題にしておきます。